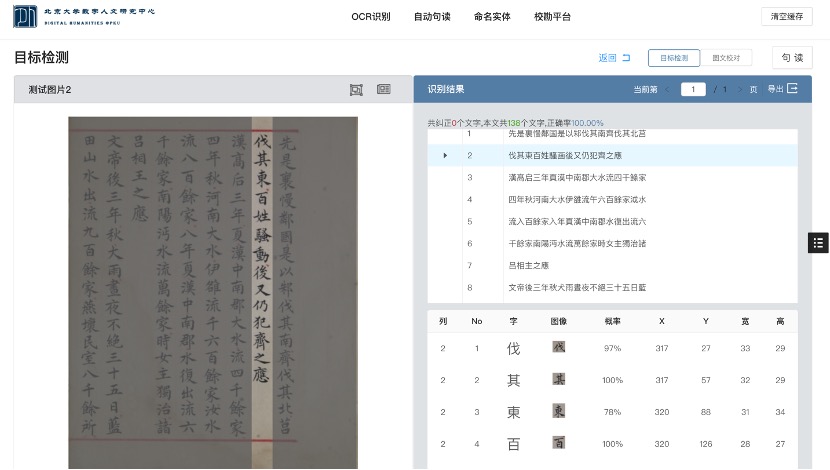
介绍
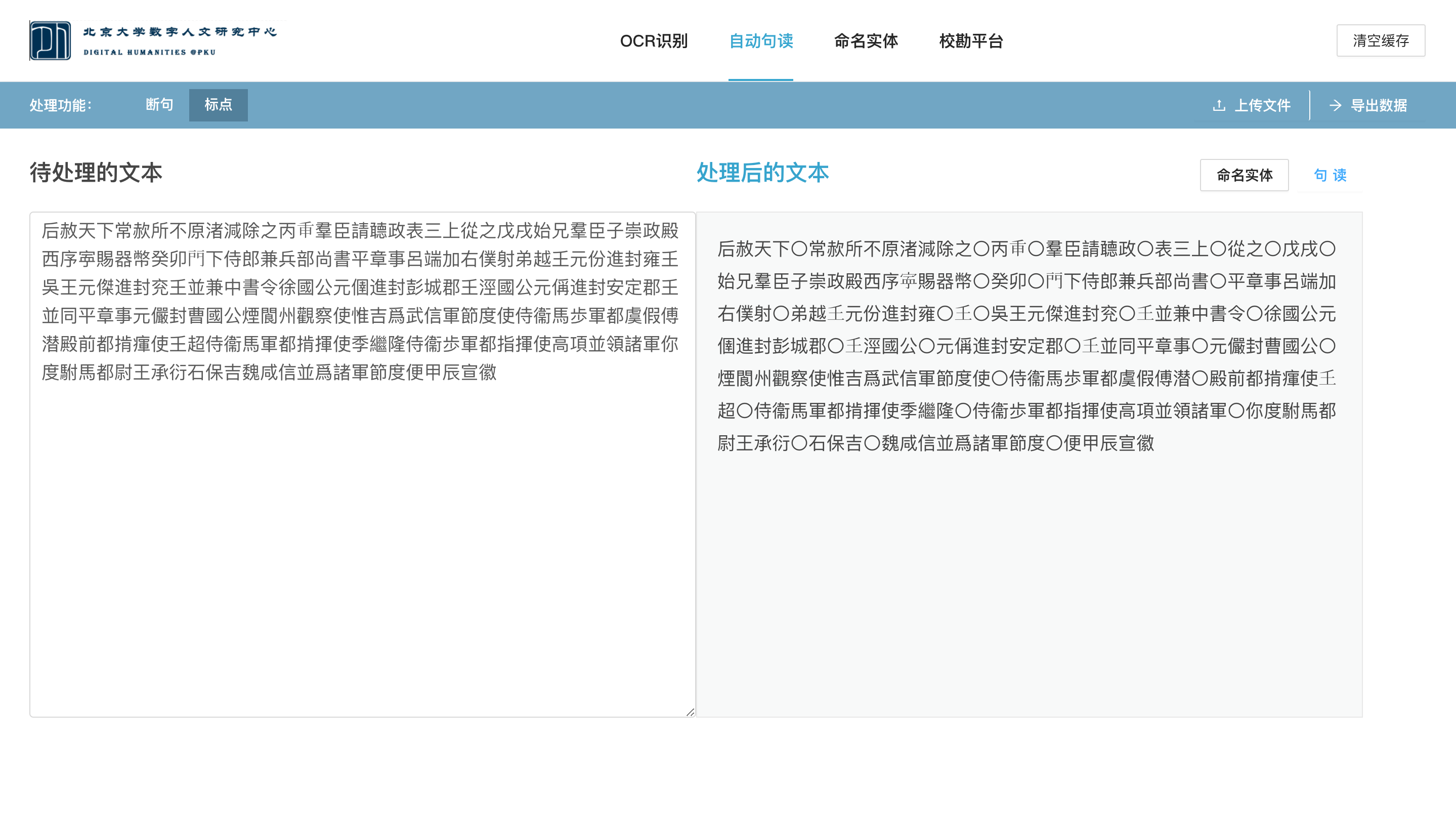
传统的古籍整理通过选定某一代表性版本作为底本,通过与其他版本的对勘校订底本文字,同时施以现代标点,标示书名、人名、地名、朝代名,旨在提供一个文字准确,标点可靠,方便阅读的排印文本。古籍自动整理平台项目按照传统古籍整理的流程,利用最先进的图像识别技术和自然语言处理技术,开发了一个从古籍图片OCR文字识别,到自动断句、命名实体识别、文本校勘的全流程的古籍整理平台原型系统。本系统的OCR识别模块集成多种图像识别技术,文字识别准确率达到92%,可进行单图片处理,也可进行批量图片处理,同时可对识别结果进行人工修改;断句模块基于最新预训练语言模型BERT,断句准确率可达93%,可同时处理简体和繁体文本;命名实体模块采用深度学习与规则的结合方式,提供了多粒度的命名实体抽取方案,同时结合主动学习对海量未标注数据进行“重要性句子”排序与甄别,从而在保证模型性能的条件下,尽可能减少人力标注成本。 古籍整理平台提供三项古籍整理基本功能:
1)OCR:可处理单张图片、也可批量处理。支持png、jpg、jpeg格式。同时提供校对功能,用户可对识别结果进行修改。
2)句读:可处理前一步OCR识别得到的文本,也可处理用户粘贴的文本。
3)命名实体识别:可对上一步句读的文本做命名实体识别,目前可识别人名、地名、官职名。也可处理用户粘贴的文本。
团队成员
句读功能:唐雪梅 严承希 陈雨航NER功能:严承希 唐雪梅 陈雨航