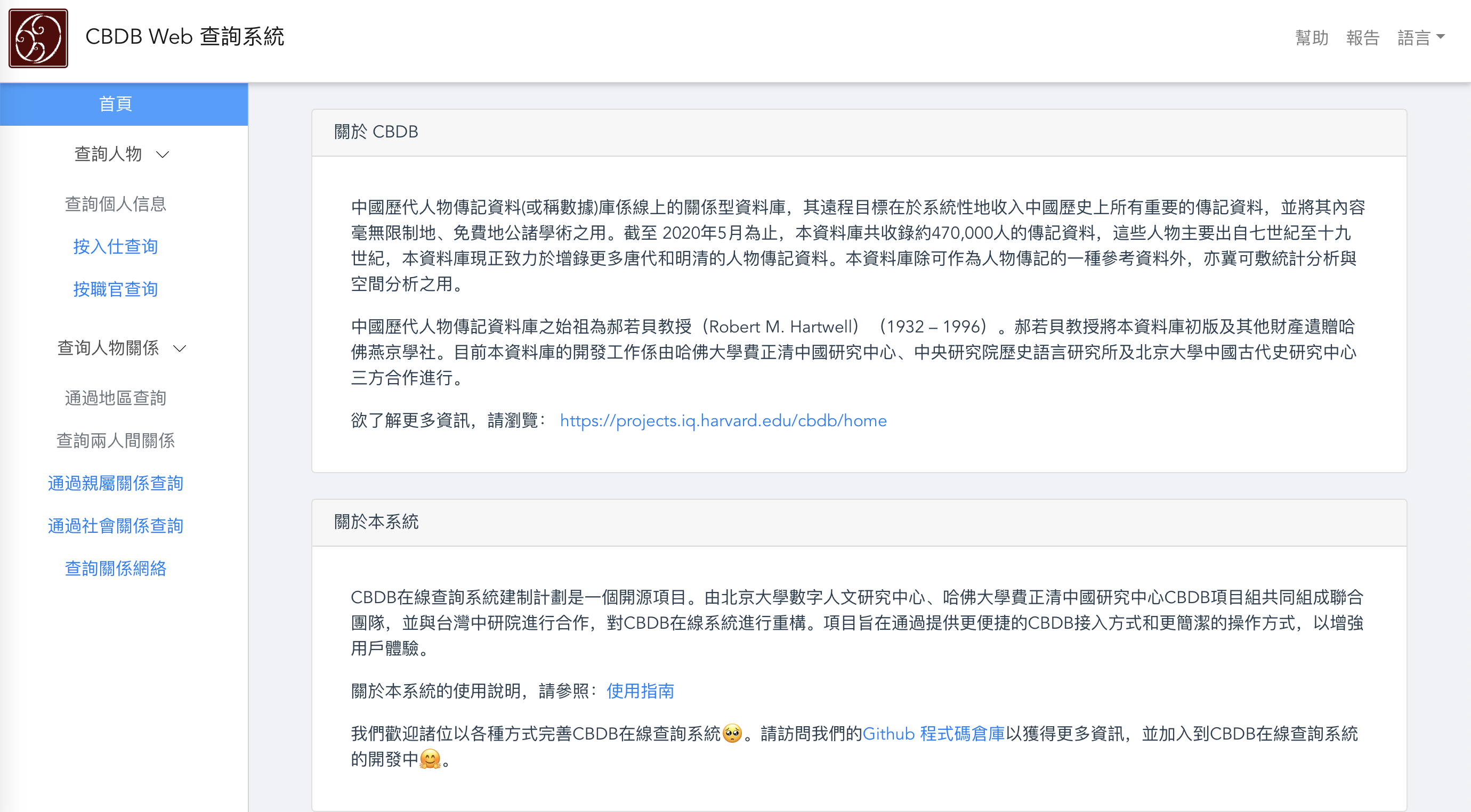
本项目在“中国历代人物传记资料库”(CBDB)的基础上提供了可视化的数据分析和交互查询等工具,为大众提供更直观、更有趣的史学知识呈现方式。本平台亦可作为专业研究人员的研究工具,探索自己感兴趣的课题。
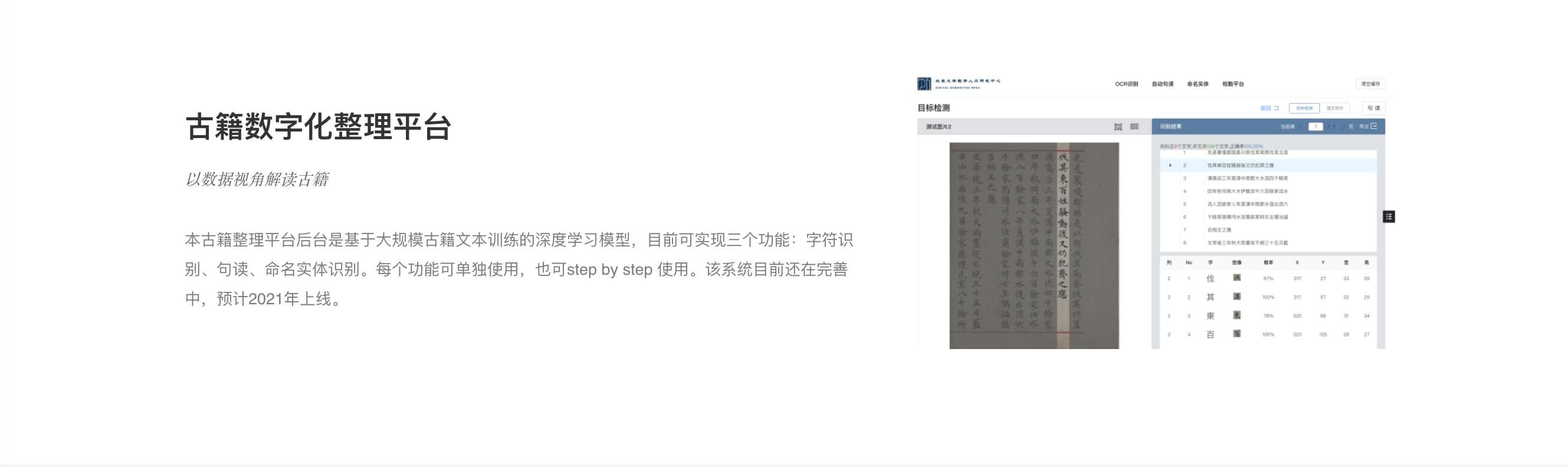
传统的古籍整理通过选定某一代表性版本作为底本,通过与其他版本的对勘校订底本文字,同时施以现代标点,标示书名、人名、地名、朝代名,旨在提供一个文字准确,标点可靠,方便阅读的排印文本。古籍自动整理平台项目按照传统古籍整理的流程,利用最先进的图像识别技术和自然语言处理技术,开发了一个从古籍图片OCR文字识别,到自动断句、命名实体识别、文本校勘的全流程的古籍整理平台原型系统。本系统的OCR识别模块集成多种图像识别技术,文字识别准确率达到92%,可进行单图片处理,也可进行批量图片处理,同时可对识别结果进行人工修改;断句模块基于最新预训练语言模型BERT,断句准确率可达93%,可同时处理简体和繁体文本;命名实体模块采用深度学习与规则的结合方式,提供了多粒度的命名实体抽取方案,同时结合主动学习对海量未标注数据进行“重要性句子”排序与甄别,从而在保证模型性能的条件下,尽可能减少人力标注成本。

中国自古重师道,门人群体是传播学术思想的重要力量。本平台通过静态的树状图和动态的网络图来呈现士人的学术师承关系,帮助用户理解学术传承脉络的衍变。本平台进一步对门人群体的籍贯分布可视化,以展示其学术影响力的范围;对门人的官职信息分布进行统计,以展示其门人的仕途成就。

“吾国近年之学术,如考古、历史、文艺及思想史等,以世局激荡及外缘薰习之故,咸有显著之变迁。将来所止之境,今固未敢断论。惟可一言蔽之曰:宋代学术之复兴,或新宋学之建立是已。华夏民族之文化,历数千年之演进,造极于赵宋之世,后渐衰微,终必复振。” ——陈寅恪《邓广铭宋史职官志考证序》

“宋元学案知识图谱系统”对240万字的《宋元学案》进行了文本处理和分析,将学案中的人物、时间、地点、著作以及它们之间的复杂语义关系提取出来构造成知识图谱,提供可视化展现、交互式浏览、语义化查询等功能。